19 articles · sorted by date
If you rely on an AI’s step-by-step explanation, you may be reading a story the model invented after the fact. That is the problem this paper targets: chain-of-thought, or CoT, can look persuasive without matching the model’s real decision process. The authors introduce CIE-Scorer, a framework for instance-level CoT unfaithfulness detection. It traces compact sentence-level circuits from informative reasoning tokens, builds internal and external reasoning graphs, and compares them with Fused Gromov–Wasserstein distance. On four datasets from FaithCoT-Bench, CIE-Scorer achieves state-of-the-art performance while reducing the cost of circuit construction. The point is not just to catch bad explanations, but to combine mechanistic interpretability signals with the text the model produces, so faithfulness can be checked more directly and more efficiently.
If a computer draws a molecule’s 3D shape the wrong way, drug design can start from a bad guess. That is the problem this paper tackles: most diffusion and flow matching models treat molecules like loose point clouds, even though real molecules have stiff bond lengths and bond angles, while torsion angles do most of the flexing. The new method, GO-Flow, splits generation into three parts that match molecular geometry: translation space with linear optimal transport, rotation space with geodesic flows on SO(3), and conformation space with entropic optimal transport. In plain English, it guides molecules through the kinds of motion they actually use instead of forcing every step through ordinary Euclidean space. Combined with equivariant neural architectures, which keep outputs consistent when molecules rotate, the approach improves geometric validity and rotation consistency. On GEOM-Drugs and GEOM-QM9, GO-Flow reaches state-of-the-art generation quality. The paper also reports that learning straighter probability paths on the right manifolds lets it sample high-fidelity molecular conformations in as few as 50 steps. That makes the model interesting not just for accuracy, but for speed too.
When a patient says “mild fatigue” or “high fever,” a doctor is not dealing with neat yes-or-no facts. The new challenge is turning messy, uncertain language into a diagnosis that can be checked. This paper tackles that problem with a neuro-symbolic system that pairs large language models with formal logic. The model first pulls out medical entities, time links, and fuzzy symptom patterns, then converts them into a symbolic knowledge base built on fuzzy logic, a way to represent shades of meaning instead of crisp facts. It uses two stages of reasoning: one to generalize diagnostic patterns from patient narratives, and another to verify diagnoses with a logic programming engine. The authors say each symptom gets a probabilistic weight, so the reasoning path can be audited and adjusted, including with physician feedback. On public benchmarks, the system performed comparably to state-of-the-art LLMs while also producing interpretable reasoning paths and formally verifiable diagnostic conclusions. That matters because medical AI is useful only if doctors can see how it reached its answer, and correct it when the evidence does not fit.
When traffic is changing block by block, simple road maps can miss the pattern that matters most. That is the problem PHGNet tackles. It predicts future traffic from historical sensor readings by using a hypergraph, a network that can link groups of nodes at once instead of only pairing them one by one. Its prototype learning mechanism groups pattern-similar nodes into hyperedges, which helps the model capture high-order interactions that change over time. PHGNet also adds a global-local node representation module to pull out features that stay consistent across time, making the dynamic hypergraph construction more reliable. For forecasting, it combines iterative residual refinement with Temporal Query Attention to improve accuracy while still supporting efficient parallel decoding. The paper reports strong results on multiple real-world datasets, with PHGNet outperforming state-of-the-art methods. For traffic management, route planning, and signal control, that means a model built to follow the messy structure of real traffic instead of treating every road connection as just a simple pair.
If you are trying to sort items or rebuild a jigsaw without labels, the real challenge is not just finding an order, but knowing which parts of that order are already certain. This paper tackles that problem in unsupervised permutation learning, where a model learns a hidden ordering directly from structure in the reordered output. The authors build on Gumbel-Sinkhorn, a differentiable relaxation that approximates permutation matrices with doubly stochastic matrices, and point out a weakness of the usual single global temperature: it forces every assignment to sharpen or blur at the same pace. Their entropy-adaptive version changes temperature locally according to assignment uncertainty, so confident matches can become discrete early while uncertain ones keep exploring. Across sorting, jigsaw reconstruction, and routing-style settings, this adaptive entropy control improves training stability and final permutation quality compared with fixed-temperature baselines. The gains are especially clear when the problem gets larger and the assignments are more ambiguous.
Traffic forecasts can make the difference between a smooth commute and a gridlocked one. The catch is that road data mixes steady rhythms, like recurring daily patterns, with sudden bursts from events and disruptions. This paper tackles that problem with ADMFormer, a transformer model (a neural network built to track relationships across data) that first separates traffic signals into dominant regularities and leftover fluctuations. It does that with a time-node adaptive gating mechanism, then sends those two parts through separate temporal branches: one for global periodic dependencies and one for high-frequency irregular changes. The model also trims the spatial links it pays attention to by using time-varying masked spatial attention, which keeps dynamic and informative connections while filtering redundant ones. On four real-world datasets, ADMFormer achieves state-of-the-art performance. That matters because traffic networks are both sparse and fast-changing, and the paper argues that treating every road connection the same can blur the very patterns forecasting systems need to see.
If you need better training data for AI, this paper argues that the best source may be a conversation, not a lone expert. The problem is that experts often skip steps they think are obvious, leaving holes in chain-of-thought (step-by-step reasoning) data. The BC Protocol pairs a domain expert with a knowledge engineer, using structured dialogue to pull out the hidden judgments behind the answer. In a controlled narrative-fiction test with 20 samples from the dual-dialogue group and 20 from the same expert writing alone, three judge models—GPT-4o, Claude Opus 4.5, and Gemini 2.5 Pro—gave the dialogue outputs a much higher score for naturalness of reasoning: 4.80 versus 1.30, with p = 2.4 × 10−8 and Cliff’s δ = 1.0. The dialogue method also showed promising but not yet significant gains in counterfactual density and reasoning-chain completeness, while solo writing had higher information density. The authors say one hour of voice dialogue can produce 10–20 usable CoT samples, and they frame this as a practical pipeline for vertical-domain LLM alignment.
When a language model has to juggle many tasks or languages, simply turning expert modules up or down may not be enough. This paper tackles that limit with RotMoLE, a mixture-of-experts system built for low-rank adapters, the small add-on modules used in parameter-efficient fine-tuning. Traditional gates mostly scale selected experts with a single number; RotMoLE adds a rotation mechanism for each chosen expert, giving the model another way to reshape how those experts contribute. The authors say this helps the system exploit and specialize its experts better, especially when only a limited set of expert candidates is available. They report empirical results on complex multi-task and multilingual training scenarios that support the approach. In plain terms, RotMoLE tries to do more than just amplify a specialist — it changes the angle of that specialist’s answer, aiming for richer behavior from the same compact machinery.
A person’s speech can carry clues about dementia in two places at once: in the words they choose and in the way they sound. This paper turns that idea into a single system for automatic dementia detection. It splits speech recordings into 10-second segments, uses HuBERT to learn acoustic features, and uses BERT to encode the transcript text. Those two streams are then joined with an attention-based Audio-Text Fusion module, while a Mutual Information Neural Estimation objective pushes the speech and transcript representations to line up more closely. The result is a fused multimodal representation for classification. The authors report that the framework was effective and robust on two public datasets: the ADReSS Challenge and PROCESS-2. The work matters because Alzheimer’s disease is progressive, and the paper notes that earlier diagnosis may help slow cognitive decline and improve patient care. In other words, this is an attempt to make subtle changes in everyday conversation easier for machines to spot.
If an AI assistant remembers yesterday’s trivia but forgets your ongoing project, the real problem is not storage — it is what gets stored. This paper argues that memory systems for large language models should not treat every user the same, because the information worth saving can differ from person to person. To test that idea, the authors introduce PerMemBench, the first benchmark for personalized memory systems, built from multi-year, multi-domain interaction histories across diverse user personas. They also study a lightweight idea called session-level storage gating, which can skip memory operations for transient sessions. The headline result is encouraging: personalization can deliver substantial retention gains when gating is perfect. But the catch is just as important — deciding accurately which sessions deserve memory is still an open challenge. That makes the paper less a finished solution than a clear map of the problem, showing where generic memory policies fall short and what must improve before long-horizon agents can remember the right things for the right people.
If you want a trading bot that reacts to rapid order-book changes, this paper says old-school Q-learning may not be the best teacher. The authors use order-flow imbalance, a compact summary of buying and selling pressure in the limit order book, to train policy-based reinforcement learning agents. They test vanilla PPO plus DeepSeekMath-inspired GRPO and GSPO, which use group-normalized updates and downside-aware shaping, on AMZN, AAPL, and GOOG. Under a simplified backtesting setup with spread-scaled rewards, these newer policies improve net average PnL, profitability, and drawdown over the Q-learning baseline. The paper’s bigger claim is simple: order-flow signals can work as a state representation for policy reinforcement learning, and group-aware PPO-style surrogates can outperform value-based methods in this directional trading setting. This is not a market-making system. The agent makes directional decisions from forecast-style states, rather than posting bid and ask quotes or managing inventory.
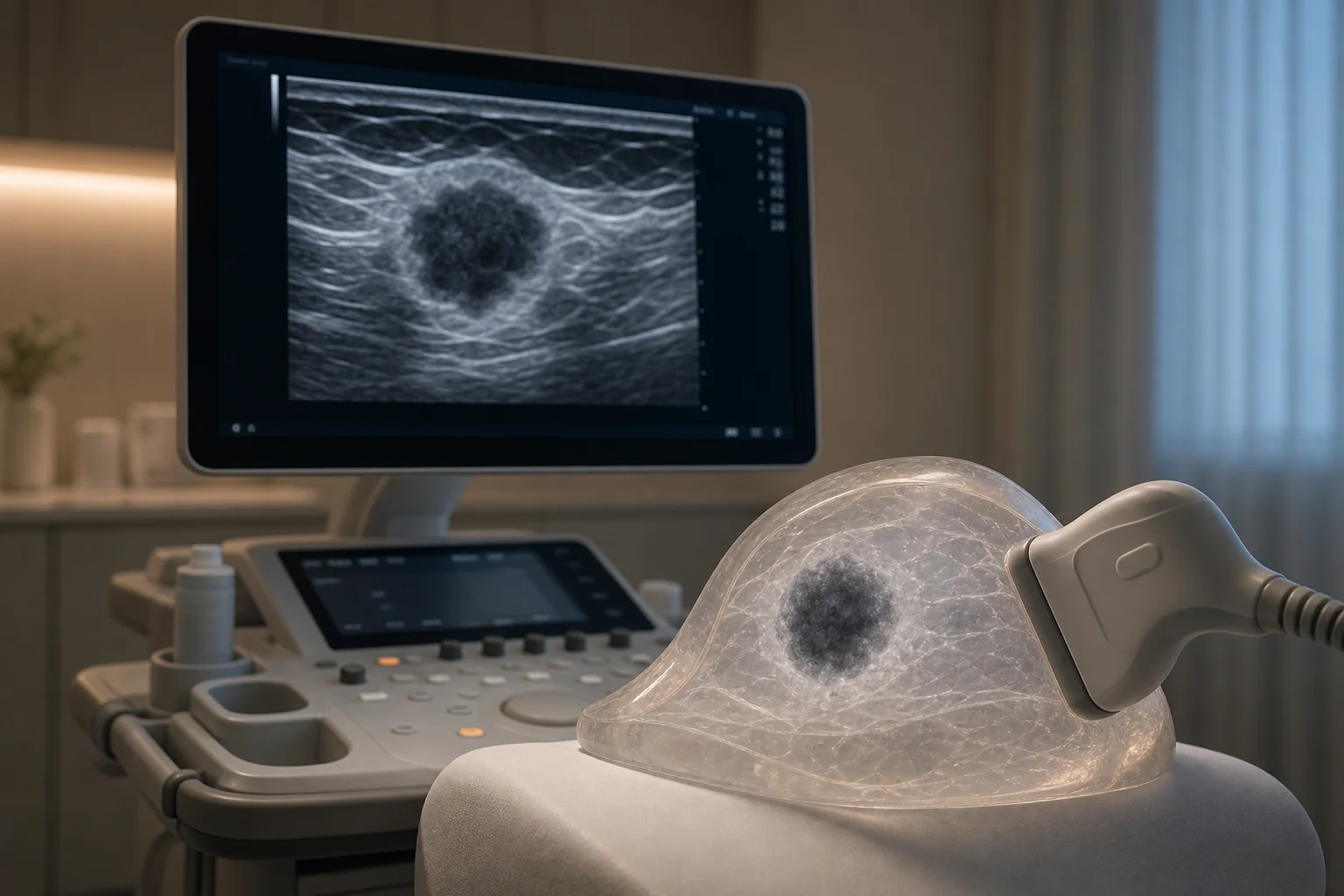
When an ultrasound image is fuzzy at the edges, even a trained eye can struggle to tell benign from malignant. This paper tackles that problem with a new neural network (a software system inspired by connected brain cells) called CSA-MoE-Net. The model combines cross-stage attention, which highlights useful tumor features while downplaying noise, with a mixture-of-experts design that looks at the whole tumor, the tumor core, and the boundary separately before fusing them together. On a balanced set of 2,129 breast ultrasound images, averaged over 20 runs, it reached 96.33% accuracy, 94.09% precision, 98.53% recall, 96.25% F1-score, and 99.50% AUC. Compared with baseline ResNet-18, those scores improved by 3.01, 0.70, 5.37, 2.98, and 5.42 percentage points, respectively. The authors say the approach needs no invasive modification and can also be added to VGG-16 and DenseNet-121, making it a practical support tool for computer-aided diagnosis.
When a network keeps changing, yesterday’s connections can miss today’s pattern. That matters for things like financial transactions, trust graphs, and social communication, where topology and node attributes evolve together. This paper introduces SiST-GNN, a dynamic graph neural network that handles time and structure in one message-passing step instead of forcing them into separate stages. The idea is to give each node a memory of its past, pair it with its current features, and let graph convolution update them together. In the paper’s tests, SiST-GNN sets a new state of the art on every public benchmark for link prediction. It outperforms the strongest prior method by 109–277% in the fixed-split setting and by 68–194% in the live-update setting. The authors also built three dynamic node-classification tasks from continuous-time event streams. On those, SiST-GNN beats the leading discrete-time baseline by 7–22% and matches continuous-time methods that read the raw events directly. The takeaway is simple: letting a graph model reason about a node’s history and its neighborhood at the same time can pay off a lot.
If your company shows up in AI answers, being near the top is only half the battle. These systems often cite just a few sources, so the real prize is being named in the response at all. This paper asks a simple question with big stakes: when two retrieved pages compete, which one gets cited first? The authors built a controlled two-document retrieval-augmented generation testbed, a setup that feeds exactly two candidate sources into the model. They ran 252,000 trials across six large language models, changing one of 18 content factors at a time and using brand anonymization plus counterbalanced source order to separate content effects from position bias. The clearest drivers of first citation were topical relevance and list position. Explicit price information and a recent timestamp also helped consistently. Completeness and trust cues gave smaller gains, while formatting-only changes had little impact. The paper also releases a reproducible evaluation protocol and a prioritized Generative Engine Optimization checklist. In an early internal pilot at Sprinklr, teams reported positive qualitative feedback on workflow usability.
When a theorem prover keeps rebuilding the same proof state, parallel search wastes most of its time. In Lean 4 with Mathlib, each branch normally reloads imports and re-runs elaboration, Lean’s type-checking step that resolves implicit details. The paper estimates import loading at about 60 seconds per branch and theorem-body elaboration at 18 to 735 seconds, and says those two costs make up more than 99% of per-branch wall time. The fix is proof-state snapshotting: capture the elaborated proof state once, then reuse it across branches instead of reconstructing it again and again. The authors implement this with a small extension to the Lean 4 language server so tactic branches can fork from the same live state. On 48 miniF2F-v2 problems, the approach delivers a 5.6 to 50 times wall-time speedup over the standard fallback, with an average 14 times speedup and a median of 9.7 times across 45 hand-crafted benchmarks. The gains grow as the number of branches grows. The paper argues this is complementary to import-level caching, which avoids repeated import loading but not theorem-body elaboration, and says the patched Lean binary and Snapshot-DSP pipeline will be released open source.
Writing quantum code can feel like assembling a circuit from a manual written in a foreign language: one wrong gate name or misplaced device setting, and the whole program breaks. PennySynth tackles that problem by pairing a large language model with a curated knowledge base of 13,389 PennyLane instruction-code pairs gathered from official repositories, community GitHub sources, and QHack archives. Its code-aware embedding model, st-codesearch-distilroberta-base, raised average retrieval cosine similarity from 0.45 to 0.726. On 74 QHack challenges from 2022, 2023, and 2024, PennySynth reached pass@5 scores of 64%, 68%, and 52%, respectively, beating Claude Sonnet 4.6 without retrieval by 28, 25, and 28 percentage points. The paper also introduces a quantum-adapted CodeBLEU metric that gives extra weight to qml.* token patterns, showing that code structure and functional correctness are related but not the same thing. The takeaway is simple: for specialized quantum programming, the right examples can make an AI assistant far more reliable.
When the world changes in sudden jumps, a normal reinforcement-learning agent can miss the signal hiding in the history. This paper’s answer is Anticipatory Reinforcement Learning, or ARL, which lifts the state space into a signature-augmented manifold, a mathematical space where the process history becomes a dynamical coordinate. The agent then keeps an anticipated proxy of the future path-law, letting it evaluate expected returns in a deterministic, single-pass way instead of branching through many stochastic possibilities. The authors say this cuts computational complexity and variance. They also prove the framework keeps key contraction properties and generalizes stably even with heavy-tailed noise. The result is a route to more stable policy learning and proactive risk management in volatile, continuous-time environments.
If your health data feels like a mountain, this paper offers a rule for knowing when more of it will actually help. The authors argue that discoverability — the chance of finding a real signal in noisy biomedical data — does not rise smoothly with sample size. Instead, it follows a zeta-like scaling law, shaped by how data spectra decay and how well signals line up across modalities. In their framework, common metrics such as AUC can be written as an effective signal-to-noise quantity that builds across spectral modes of an encoder and a cross-modal operator. That matters because the model’s representation can change the curve: sparse models, low-rank embeddings, and multimodal contrastive objectives can push useful signal into earlier, more stable modes and improve sample efficiency. The paper also predicts cross-over behavior, where simpler models win when data are scarce, but higher-capacity or multimodal encoders take over after enough data stabilizes extra degrees of freedom. The authors say this could help anticipate when scaling data, improving representations, or adding modalities like text is most likely to accelerate discovery in areas such as multimodal disease classification, imaging genetics, functional MRI, and topological data analysis.
A network with random weights can match, and even beat, a trained one in the brain’s earliest visual stages. This paper compared four learning rules—backpropagation, feedback alignment, predictive coding, and spike-timing-dependent plasticity—on the same convolutional neural network (a layered image model) and checked how closely their internal patterns matched human fMRI scans. The test set came from THINGS-fMRI: 720 stimuli seen by 3 subjects, analyzed with representational similarity analysis, or RSA, which asks whether two systems organize images in similar ways. At V1/V2, the untrained random-weights baseline scored higher than backpropagation, with ρ = 0.076 versus 0.034. STDP had the best trained score at V1, while feedback alignment was the weakest there, at ρ = 0.012. At LOC, only backpropagation reliably beat the random baseline. By IT, all five conditions converged to similar values, and no trained rule stood out. The authors say early visual alignment seems driven mainly by architecture, while learning rules matter more in the middle of the hierarchy.